[Listening to: ‘Moscow Nights’ by the Feelies; ‘Get The Rhyme Right’ by Matthew Dear; ‘The Supermen’ by David Bowie; ‘Don’t Carry It All’ by Low; ‘Black Like Me’ by Spoon; ‘Mogwai Fear Satan’ by Mogwai’; ‘Fangela’ by Here We Go Magic; ‘White Light/White Heat’ by the Feelies; ‘Blue Cash’ by Deerhoof; ‘Milk Man’ by Deerhoof; ‘Cool Cool Water (Version 2)’ by the Beach Boys; ‘Photojournalist’ by Small Black; ‘King Kong Kitchie Kitchie Ki-Me-O’ by Chubby Parker & His Old Time Banjo; ‘Acid Food’ by Mogwai]
On April 1, 2017, I gave a presentation with the same title as this post at the English Australia Queensland Branch PD Fest. It started with 10 minutes’ discussion in groups of 3-4 of these questions:
 I roamed around as much I could, listening to some of the groups and joining in a little. Then I led a plenary discussion. It was difficult within a 50-minute session to go into a lot of depth as a group but here are some thoughts and recollections:
I roamed around as much I could, listening to some of the groups and joining in a little. Then I led a plenary discussion. It was difficult within a 50-minute session to go into a lot of depth as a group but here are some thoughts and recollections:
- The focus was entirely on ‘tests’ and not on any other type of assessment (e.g., continuous, dynamic, alternative).
- ‘Macro-skills’ tend to be tested separately, rather than integrated.
- These tests are scored and the scores aggregated.
- IELTS came up a number of times, particularly I think in terms of its washback on the curriculum (i.e., narrowing it).
- One participant commented that he appreciated the opportunity to discuss the above questions because they did not often come up.
- Another participant mentioned that responsibility for testing within his college had recently been removed from teachers and it had become more standardised and centralised.
My broad impression was that, at the various colleges represented by the 20-odd participants, similar sorts of things were assessed in similar sorts of ways. I also sensed a fair bit of dissatisfaction and discomfort with the status quo and the seemingly inescapable influence of IELTS. That could just be confirmation bias at work, though 🙂
The final comment to the group before I moved on to the body of my session was regarding the challenges of standardising assessment. My response was that, globally, a lot of time, effort and money is put into getting teachers/assessors to agree on scores/grades/ratings for students’ work in a possibly futile pursuit of the holy grail of optimal inter-rater and intra-rater reliability. This was a wonderful segue into my thesis: where there is a clear rationale for the design of assessment at our colleges, it is likely to be largely about maximising reliability (even though it might be referred to mistakenly as ‘validity’). The desire for efficiency may also be an influential factor.
Defining ‘reliability’
What is ‘reliability’? As I discussed in an earlier post, Dr Evelina D. Galaczi and Dr Nahal Khabbazbashi offer a definition which both Cambridge English and English Australia appear to endorse: ‘reliability’ is
how dependable the scores from the test are or to put it differently how can we make sure that the scores that we give in a test reflect the learners’ actual ability and not whether for example the examiner happened to be in a bad mood that day and was particularly harsh in giving marks.
This is not actually very helpful so let’s try something clearer. The National Council of Measurement in Education (NCME) tells us that reliability is
The characteristic of a set of test scores that relates to the amount of random error from the measurement process that might be embedded in the scores. Scores that are highly reliable are accurate, reproducible, and consistent from one testing occasion to another. That is, if the testing process were repeated with a group of test takers, essentially the same results would be obtained. Various kinds of reliability coefficients, with values ranging between 0.00 (much error) and 1.00 (no error), are usually used to indicate the amount of error in the scores.
Similarly, the Standards for Educational and Psychological Testing (2014) state that reliability is demonstrated by the “correlation between scores on two equivalent scores of the test, presuming that taking one form has no effect on performance on the second form” (p. 33). In reality, it’s not really possible to give one test-taker the same test twice without their first experience affecting the other so equivalent – or ‘parallel’ – forms of a test have to be created.
Measuring error is important in Classical Test Theory and Classical Test Theory is important
The first part of the NCME definition above indicates the importance of measuring the ‘random error’ component of a test score. Jones (2013) provides a useful illustration of the two main components of a test score and some of the sources of error: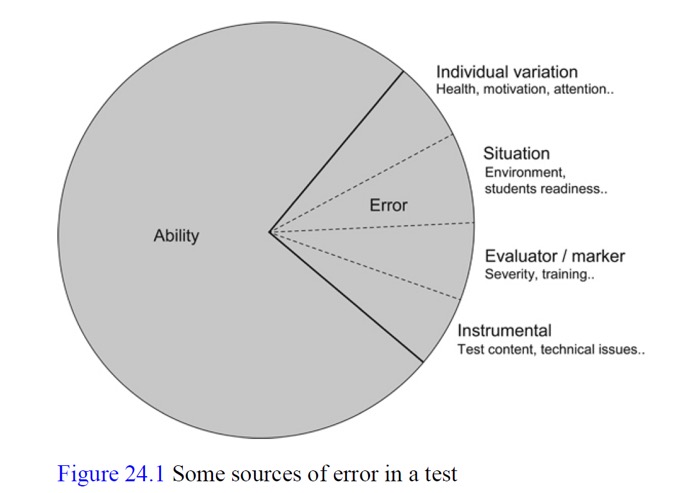
The whole circle represents the test score or what, in Classical Test Theory (CTT), is called the ‘observed score’. CTT also refers to the ‘Ability’ component in Jones’s diagram as ‘true score’ and gives us this equation:
observed score = true score + error
This equation is fundamental to CTT and CTT is, according to Brown (2013), “alive and well” as “probably the dominant psychometric theory actually applied to the problems of language testing in real-world language teaching situations” (p. 771). As evidence of the continuing dominance of CTT more than 100 years after its emergence, Brown (2013, p. 774) states that:
many (even most) people who take any university courses in language testing are trained primarily in CTT. Brown and Bailey (2008) show that the vast majority of topics (and probably course hours) is spent on topics that are within the general area of CTT.
Brown argues that, because of this training and also the CTT perspective taken in the most commonly used textbooks in Master’s level teacher training programs,
most language teachers and administrators doing proficiency or placement testing in their programs are doing it on the basis of their training in CTT during MA or PHD programs (2013, p. 775).
That has certainly been my experience: I was trained in CTT during my MEd (TESOL) and that’s the approach I’ve taken to assessment through most of my career in education.
Measuring and minimising error
The idea that a person’s observed score is made up of their true score (correlating directly with their ability) and error seems self-evident. What it leads to is a need to measure and minimise error so that it is contributing as little as possible to a person’s observed score and, thus, the observed score correlates more closely with their ability.
This is important because it improves the fairness of the test. Imagine that two test-takers have the same essay-writing ability but they get different (observed) scores on a test which requires them to write an essay. Why? Because the two essays were marked by two different people who differ considerably in their severity. This is unfair for the test-takers and the source of this unfairness must be addressed, thus reducing the error component of their test score, likely through training activities – ‘standardisation’ – for the raters.
Depending on the types of test tasks used, a battery of statistical analyses associated with CTT may also be conducted, including descriptive statistics, item facility, item discrimination, distractor efficiency analysis, reliability estimates and the standard error of measurement (Brown, 2013). These will help to determine how ‘accurate, reproducible, and consistent the scores are from one testing occasion to another’ (NCME) and identify, for example, specific test items which are subject to high levels of error, i.e. ‘faulty’.
Test specifications
I mentioned above the importance of parallel tests; how would we know if two forms of a test are in fact parallel? The Standards for Educational and Psychological Testing (2014) state that parallel “forms of test are considered interchangeable, in the sense that they are built to the same specifications” (p. 35). Hence the importance of test specifications, a “generative blueprint from which many equivalent test items or tasks can be produced” (Davidson, 2013, p. 486). The skills to be tested are specified, as well as the number of items required per skill and how those items are constructed and scored.
Before this can be done, the ability that we want to measure – ‘language ability’ – needs to be broken down into smaller bits (e.g. sub-skills such as ‘understanding the main idea’ or ‘distinguishing between facts and opinions’) so that each can be tested more reliably. A one-to-one match between sub-skill and test item means that CTT’s favoured statistical analyses can be performed, based as they are on the assumption of ‘unidimensionality’: only one thing (‘understanding the main idea’) is being tested and scored. To put it another way, if a test item is not unidimensional, then error cannot be measured and reliability cannot be estimated. Once all the sub-skills have been measured, each with several corresponding items (and the more the better), the sub-scores can be aggregated to produce an overall score, purportedly representing ‘language ability’.
This is essentially psychometrics – ‘measuring the mind’. It’s a scientific and objective approach to assessment (which actually originated in the physical sciences and then was applied to education at the end of the 19th century, creating the educational measurement discipline) but, in the context of language assessment, how plausible is it? Can we really separate out ‘language ability’ into its component parts and measure each of them scientifically and objectively as if we are measuring temperature?
I don’t think so and I don’t accept the assumptions underlying CTT and psychometrics. I don’t believe it is possible to quantify a psychological construct, whether it is intelligence, emotional intelligence, growth mindset, anxiety or language ability, at least not to the extent that makes statistical analyses meaningful. Also, a mind – unlike temperature – knows when someone is trying to measure it and is changed by the attempted act of measurement.
This is where I think we’re going wrong: we’re persisting with an assessment theory which is fundamentally at odds with what it is we’re trying to assess.
So what?
Fulcher, Kemp and Davidson (2011, pp. 8-9) state that
Measurement-driven scales suffer from descriptional inadequacy. They are not sensitive to the communicative context or the interactional complexities of language use. The level of abstraction is too great, creating a gulf between the score and its meaning.
For students and teachers, this ‘gulf’ means that the formative promise of assessment is unfulfilled: teachers are unable to give students the feedback they need in order to work out what to do next. Or, worse, they aren’t aware of the ‘gulf’ and are misled. This is particularly damaging if a student receives a test score which is lower than what they expect or lower than what they scored on their last test. How are they supposed to interpret that? Has their ability declined? What do they do next?
Broad (1996, p. 271), focusing on standardised writing assessment, judges
the stupendous energy pumped into achieving statistical reliability … to be a waste of precious resources, destructive to our students, to our colleagues, and to our project as teachers of literacy. If we let go of the quantification of writing ability in large-scale assessments, we could also dispense with our fixation on statistical reliability [and vice versa]. Rather than allowing a number to be the evaluative output of what is otherwise a rhetorically sophisticated process, we could offer something more useful and more appropriate theoretically: positioned, situated or located assessment.
The idea of ‘positioned, situated or located assessment’ points us to the alternative to psychometrics proposed by Pamela Moss: hermeneutics.
Hermeneutics
‘Hermeneutics’ means literally ‘the art of interpretation’. Compared to psychometrics, it expands “the role of human judgment to develop integrative interpretations [of a student’s collected language performances] based on all the relevant evidence” (Moss, 1994, p. 4). This evidence could include the ‘interpretations’ of the individuals who are most familiar with the student, i.e. the teacher, the student him/herself and his/her peers, hence Broad’s advocacy of ‘positioned, situated or located assessment’.
For psychometricians, this would result in less standardised forms of assessment which “present serious problems for reliability” because they
typically permit students substantial latitude in interpreting, responding to, and perhaps designing tasks; they result in fewer independent responses, each of which is more complex, reflecting integration of multiple skills and knowledge; and they require expert judgment for evaluation (p. 6)
This kind of latitude would lead to unacceptably low levels of reliability and thus tends to be deliberately designed out of many assessment systems. However, from this hermeneutic perspective, the “detached and impartial” standardised assessment favoured by psychometricians appears less fair and “arbitrarily authoritarian and counterproductive, because it silences the voices of those who are most knowledgeable about the context and most directly affected by the results” (pp. 9-10)
Portfolio assessment
The archetypal hermeneutic assessment is the portfolio. There are lots of different types of portfolio assessment systems but imagine one in which:
- Students take responsibility for collecting samples of their spoken and written work to meet certain curriculum goals or requirements
- Select their best pieces along with the drafts which teachers have provided formative feedback on (but no grades or scores)
- Write a cover letter explaining why they have met the curriculum goals with reference to the actual portfolio contents
- Finally submit this so it can be assessed by two teachers, who read the cover letter and portfolio contents where necessary and then, for summative purposes, rate it as ‘Unsatisfactory’, ‘Satisfactory’ or Excellent’.
This system, inspired by White’s (2005) ‘Phase 2 scoring’ model, would establish a more appropriate balance between the summative (summing up the evidence as a whole, rather than awarding and aggregating scores for several separate performances) and formative functions of assessment. It would probably also present a range of practical challenges in many educational contexts. These can be overcome but first we have to “dispense with our fixation on statistical reliability,” otherwise we’re likely to persist with our “arbitrarily authoritarian and counterproductive” efforts to measure language ability scientifically and objectively.
