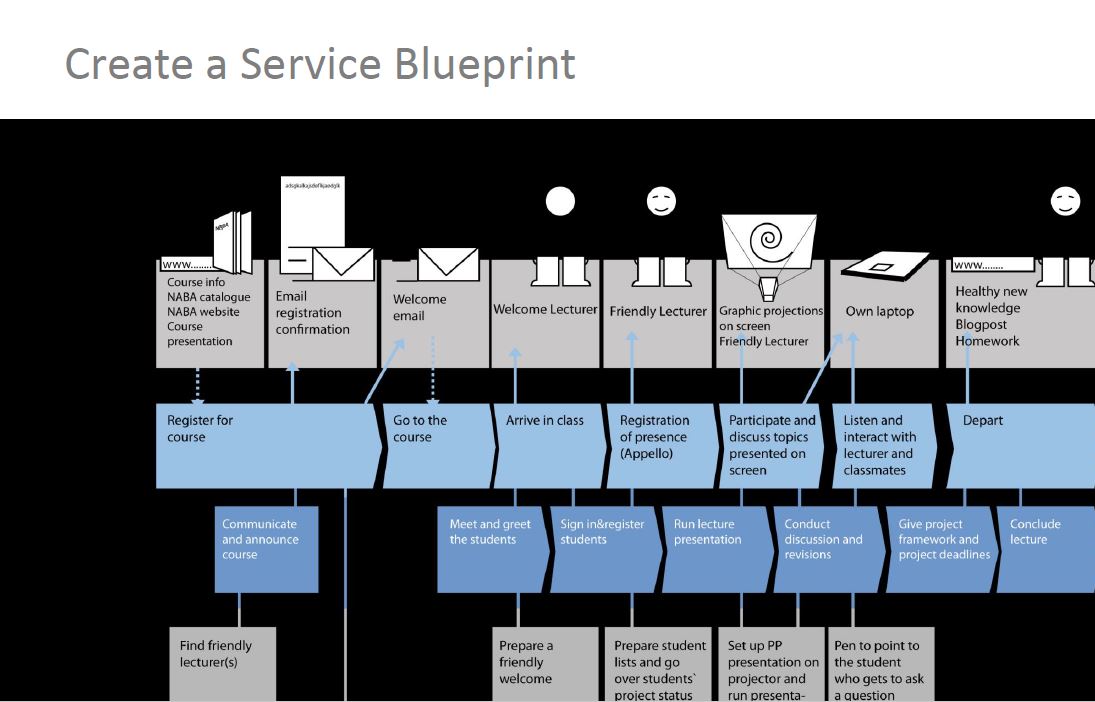
During the ‘Customer Service Management’ module of the IDLTM last year, I encountered Shostack’s notion of the ‘service blueprint’ via this 1997 article by John Walker. It involves “mapping out all the various interactions and actions that occur when customer and company meet.”
This is a useful concept to apply to the accumulation, storage, transfer, analysis and use (paraphrasing Harvey 2005) of student data as, increasingly, these ‘various interactions and actions’ are mediated by internet-enabled technologies. Hence, the ‘student data blueprint’.
Imagine a student of yours, perhaps a refugee or one who comes from a country with an authoritarian government who might be very interested to know what their citizen is up to, e.g. China, Saudi, Venezuela, Thailand, or Russia. Now consider the following questions:
 If you work in a country with a highly-regulated ELT sector (here in Australia it’s referred to officially as ‘ELICOS’ = English Language Intensive Courses for Overseas Students), you already have a privacy policy. No doubt it’s taken very seriously by the staff, management and owners of your organisation and complies with relevant legislation. But does it address the above questions?
If you work in a country with a highly-regulated ELT sector (here in Australia it’s referred to officially as ‘ELICOS’ = English Language Intensive Courses for Overseas Students), you already have a privacy policy. No doubt it’s taken very seriously by the staff, management and owners of your organisation and complies with relevant legislation. But does it address the above questions?
The reality for our students as they interact with our organisations is something like this:

(The illustration by Jordan Awan accompanies a recent article called ‘Facebook Should Pay All of Us‘ by Tim Wu)
If the character on the left is our student visiting our website on their own mobile device, who is the thief? It could be any or all of the following:
- The student’s mobile phone company, which may be using something like a ‘tracking header‘, ‘permacookie’ or ‘supercookie’ to track them
- A random hacker
- A terrorist organisation
- A government security agency, perhaps that of their own country, the UK or the US
- Third party trackers
- Data broking firms
It’s the last two on this list that I’d like to focus on now.
Third party trackers
‘Third party trackers’ are basically companies which use ‘cookies‘ to follow internet users as they navigate from one website to another. A cookie, or ‘persistent identifier’ is a small packet of data which contains a unique number that allows websites to identify you (Schneier 2015, p. 47). When you visit this page, for example, three companies – Twitter, Gravatar and WordPress – each ‘set a cookie’ (i.e. create a unique ID number for your browser and send it to your browser) and, depending on your browser privacy settings, these three companies can then track you as you navigate to other sites where their trackers are also operating. In the case of Twitter, for example, this includes every site with a ‘Tweet this’ button.
As I understand it (and my understanding is fairly limited), this technology serves two main purposes. One is to facilitate targeted advertising: as you navigate to various sites – looking at rucksacks on eBay or checking out listings on RealEstate.com – data slowly accumulates which is suggestive of your interests, occupation, income, age, gender, sexuality, marital status, etc. This will probably also be combined with data about whether you use a Mac or PC, what your IP address is, your location, dates and times of your web use, the browser you use, etc. Similarly, companies like New Relic use all this data to provide detailed reports to their clients about the effectiveness of their websites and apps – for a fee, of course. New Relic’s clients then use this data – your data – to improve their service, website or app.
Using the browser extension Ghostery, I conducted a survey this week of third party trackers on the websites of 25 universities and private companies with English language schools in Brisbane.
- 41 separate trackers are tracking visitors of these 25 websites.
- Each individual website has on average 3.44 trackers.
- One website has no trackers at all.
- One website has eight trackers.
Google Analytics is on 21 of the 25 sites; of the remaining four, three had another tracker owned by Google (DoubleClick, Google Tag Manager, Google AJAX Search API, Google AdWords Conversion, Google Translate, Google+ Platform, or Google Dynamic Remarketing). This means that, even if you have never actually used a Google app or Google Search, Google still has your data. It has been estimated that, because so many websites use these Google services, the “probability of providing data to Google when visiting 5 random websites, without actively using any Google service, is 99.35%.”
This is the complete list of all the trackers I was able to identify, each with a link to details from Ghostery about what sort of data they collect.
- AddThis
- AdRoll
- Alexa Metrics
- BugHerd
- ChartBeat
- ClickDimensions
- Crazy Egg
- DoubleClick
- DoubleClick Floodlight
- Facebook Connect
- Facebook Social Graph
- Facebook Social Plugins
- FreakOut
- GetKudos
- Google Analytics
- Google AdWords Conversion
- Google AJAX Search API
- Google Dynamic Remarketing
- Google Tag Manager
- Google Translate
- Google+ Platform
- Hotjar
- HubSpot
- KissInsights
- LivePerson
- Lucky Orange
- Lyris ClickTracks
- Marin Search Marketer
- Marketo
- Mixpanel
- MyFonts Counter
- New Relic
- Piwik Analytics
- ScoreCard Research Beacon
- Sizmek
- SumoMe
- Tealium
- Twitter Badge
- Twitter Button
- TypeKit by Adobe
- Visual Website Optimizer
- Yandex.Metrics
It may not be obvious from their Privacy Policy, but, according to Ghostery, New Relic collects the following types of data:
- Anonymous (Browser Information, Date/Time, Hardware/Software Type, Serving Domains)
- Pseudonymous (IP Address (EU PII))
- PII (PII Collected via 3rd Parties)
‘PII’ stands for ‘personally identifiable information‘ and New Relic apparently shares this with third parties. Don’t take the ‘PII’ concept too literally though: the line between data that’s anonymous and personally identifiable is very blurry and a few seeminly innocuous pieces of information can be de-anonymised with startling ease.
I don’t know about you, but this makes my head spin!
Data brokers
One of the third parties that New Relic shares data with may be a data broking firm. According to Bruce Schneier (2015, p. 51), these firms have traditionally combined data from “four basic surveillance streams”:
- Companies’ (e.g. hotels and airlines) records of their own customers
- Direct marketing
- Credit bureaus
- Government
The breadth of and depth of information that data brokers have is astonishing. They collect demographic information: names, addresses, telephone numbers, e-mail addresses, gender, age, marital status, presence and ages of children in household, education level, profession, income level, political affiliation, cars driven, and information about homes and other property. They collect lists of things you’ve purchased, when you’ve purchased them, and how you paid for them. They keep track of deaths, divorces, and diseases in your family. They collect everything about what you do on the Internet. (Schneier 2015, p. 52, emphasis added)
There are many of these data brokers around but one of the oldest and biggest is Acxiom. According to Natasha Singer (2012), Acxiom has “information about 500 million active consumers worldwide, with about 1,500 data points per person.” They use all this data to create a profile of you and sell it as part of ‘data packages’.
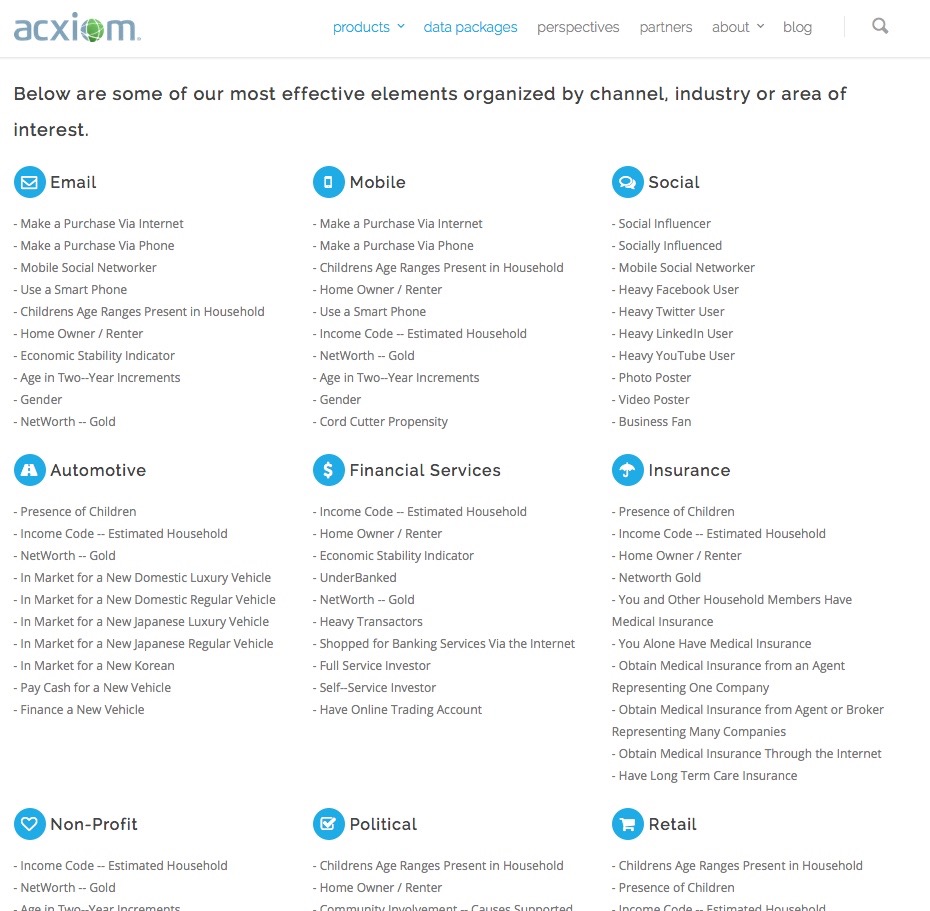
And yes, in case you’re wondering, Acxiom’s database – like so many other organisations – has been hacked into.
The moral is that you should never assume that you know who has your data or what they’re doing with it. Or your students’ data, for that matter. It is a valuable commodity and there are many companies out there who want to collect as much of it as possible and sell as much of it as possible.
What happens when your students access your Facebook page?
This is where it’s useful to read Facebook’s Privacy Policy and Terms & Conditions. Except that’s likely to be highly tedious and not very enlightening.
One helpful tool is Terms of Service; Didn’t Read.
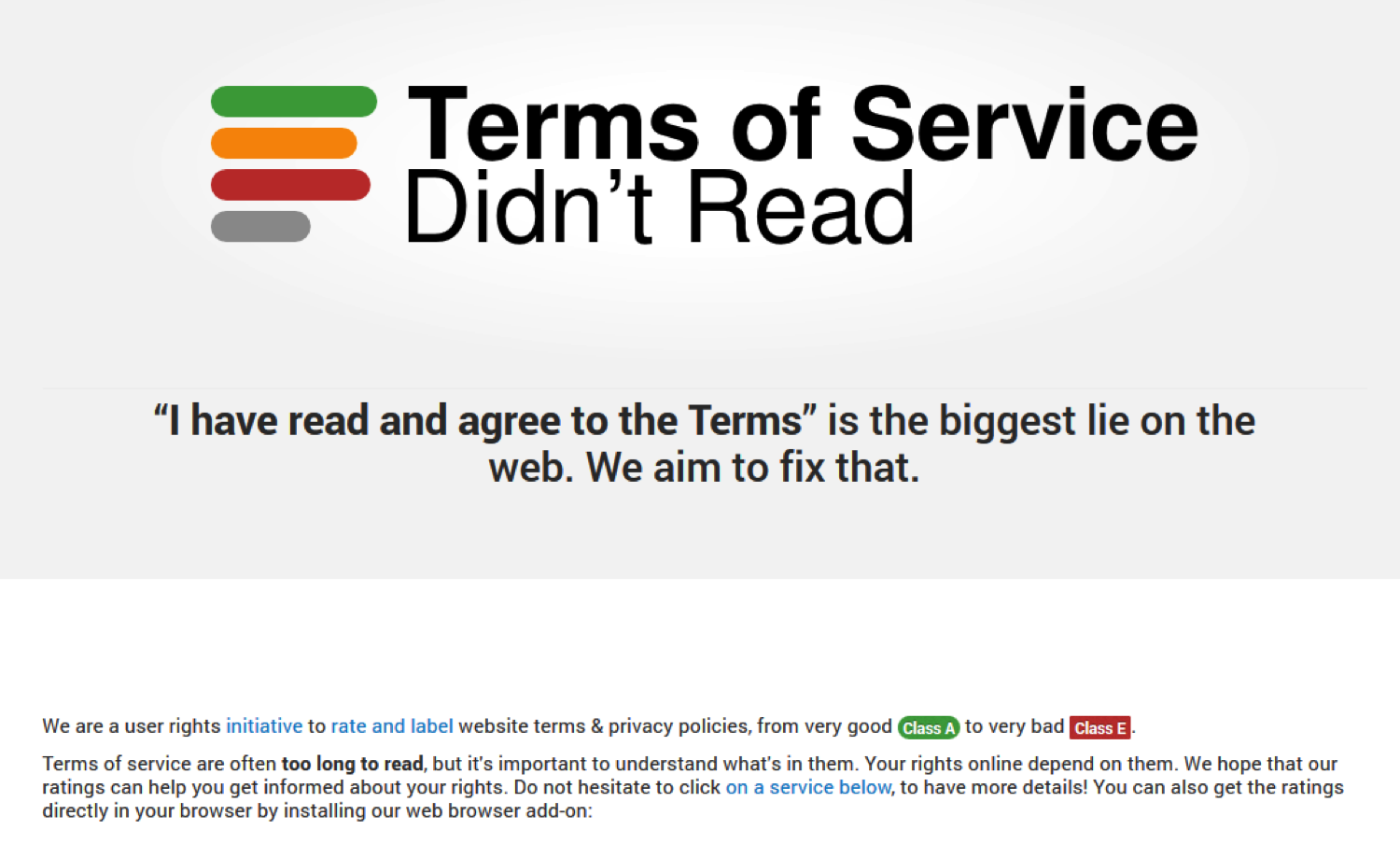
You can install it as an unobtrusive web browser extension and then use it to help understand the Terms of Service of various websites you visit, including Facebook. For example, it makes clear the following points about our relationship with Facebook:
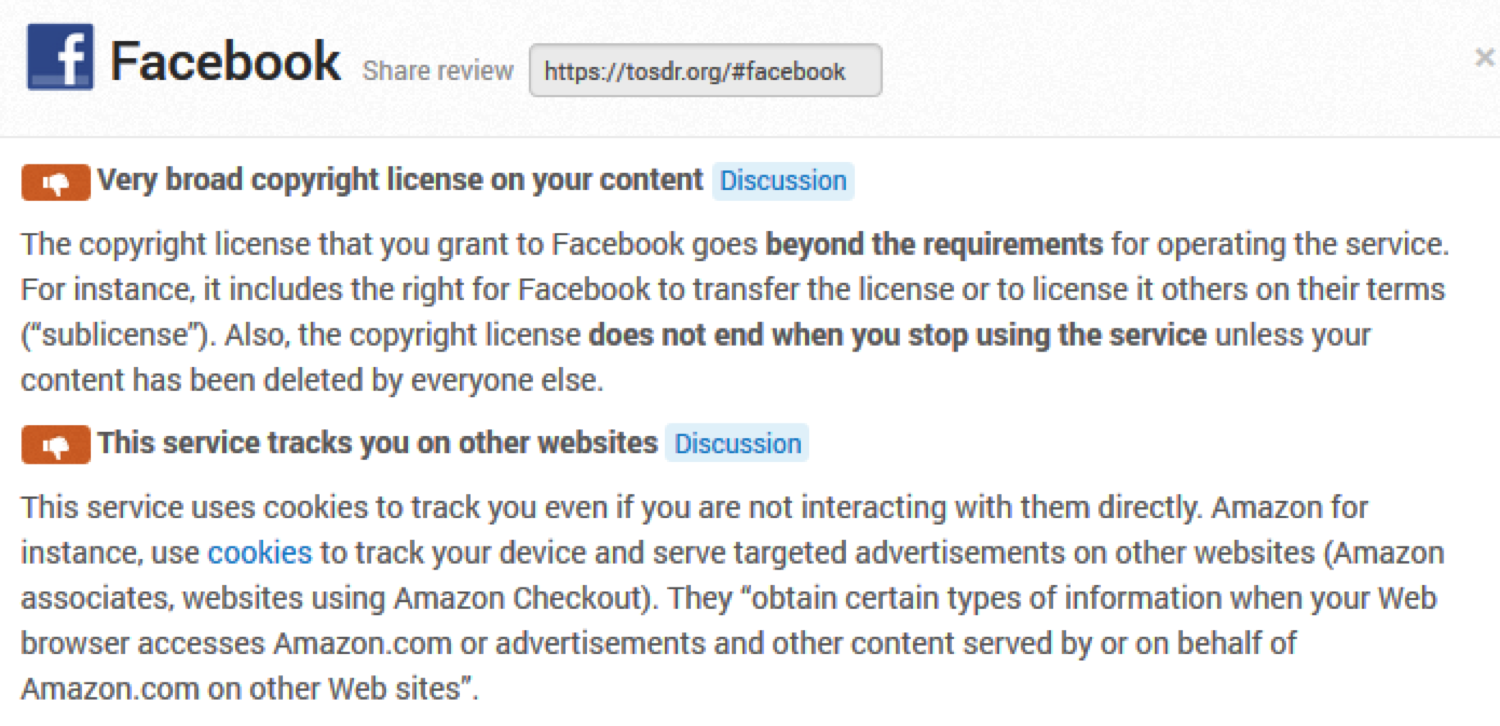
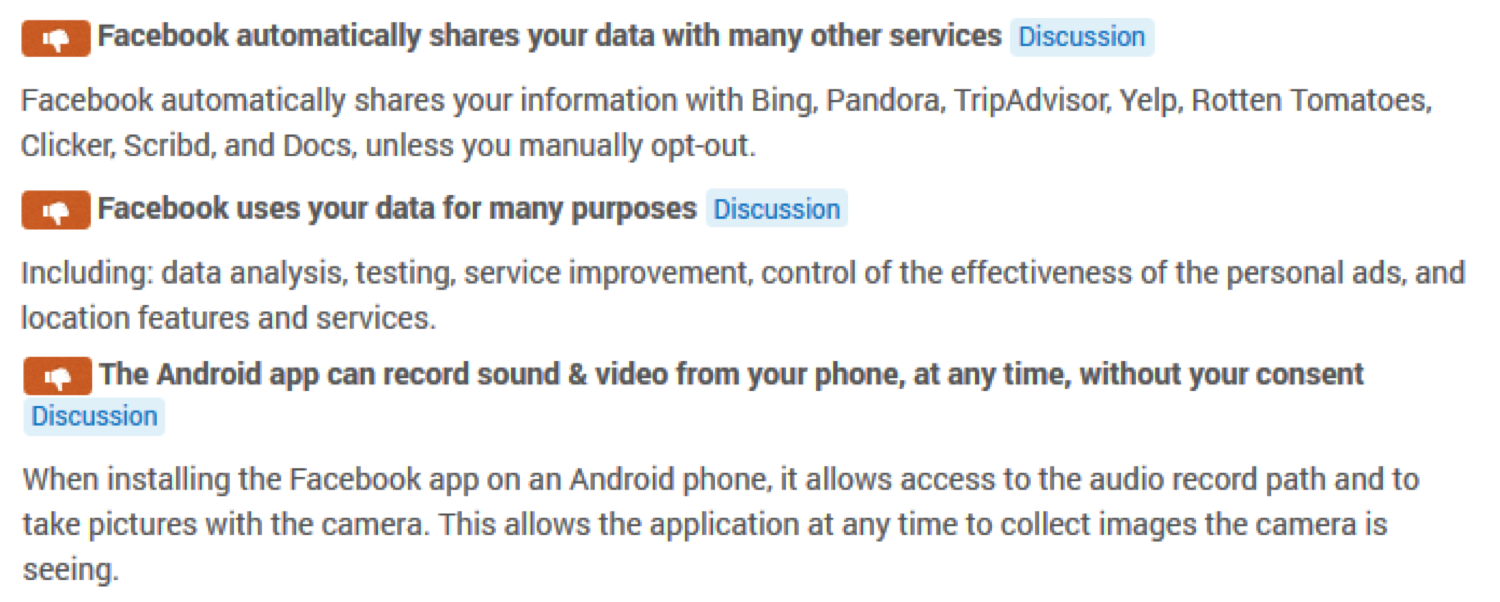
A couple of notable points:
- Any piece of hardware such as a microphone or camera on an internet-enabled device can be accessed remotely and without your consent. That also extends to anything with an IP address such as a car.
- It uses your students’ data, among other things, for ‘service improvement’. One way to interpret is that it uses their data to improve the value of its service and the value of the company and the dividends it pays to its shareholders.
For this reason, and for others discussed above, Tim Wu (2015) argues that, when “billions of people hand data over to just a few companies, the effect is a giant wealth transfer from the many to the few.”
Even if we assume that the data is 100% secure and is never accessed by ‘bad actors’ and that as individuals we aren’t too worried about our data being gathered and used in this way, should we be encouraging or, worse, requiring our students to participate?
Part 1: Attitudes to educational technology
